Глава 3. Кодирование информации
3.11. Алгоритмы сжатия.
Сжатие данных осуществляется либо на прикладном уровне с помощью программ сжатия, таких, как ARJ, либо с помощью устройств защиты от ошибок (УЗО) непосредственно в составе модемов по протоколам типа V.42bis.
Очевидный способ сжатия числовой информации, представленной в коде ASCII, заключается в использовании сокращенного кода с четырьмя битами на символ вместо восьми, так как передается набор, включающий только 10 цифр, символы "точка", "запятая" и "пробел".
Среди простых алгоритмов сжатия наиболее известны алгоритмы RLE (Run Length Encoding). В них вместо передачи цепочки из одинаковых символов передаются символ и значение длины цепочки. Метод эффективен при передаче растровых изображений, но малополезен при передаче текста.
К методам сжатия относят также методы разностного кодирования, поскольку разности амплитуд отсчетов представляются меньшим числом разрядов, чем сами амплитуды. Разностное кодирование реализовано в методах дельта-модуляции и ее разновидностях.
Предсказывающие (предиктивные) методы основаны на экстраполяции значений амплитуд отсчетов, и если выполнено условие
Ar - Ap > d,
то отсчет должен быть передан, иначе он является избыточным; здесь Ar и Ap - амплитуды реального и предсказанного отсчетов, d - допуск (допустимая погрешность представления амплитуд). Иллюстрация предсказывающего метода с линейной экстраполяцией представлена рис. 3.3. Здесь точками показаны предсказываемые значения сигнала. Если точка выходит за пределы "коридора" (допуска d), показанного пунктирными линиями, то происходит передача отсчета. На рисунке передаваемые отсчеты отмечены темными кружками в моменты времени t1, t2, t4, t7. Если передачи отсчета нет, то на приемном конце принимается экстраполированное значение.
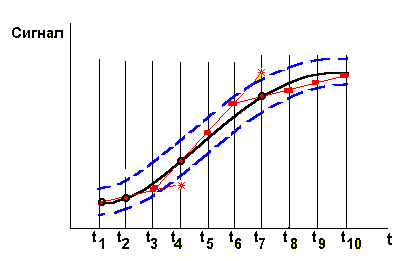
Рис. 3.3. Предиктивное кодирование
Методы MPEG (Moving Pictures Experts Group) используют предсказывающее кодирование изображений (для сжатия данных о движущихся объектах вместе со звуком). Так, если передавать только изменившиеся во времени пиксели изображения, то достигается сжатие в несколько десятков раз. Этот алгоритм сжатия используется также в стандарте Н.261 ITU. Методы MPEG становятся мировыми стандартами для цифрового телевидения.
Для сжатия данных об изображениях можно использовать также методы типа JPEG (Joint Photographic Expert Group), основанные на потере малосущественной информации (не различимые для глаза оттенки кодируются одинаково, коды могут стать короче). В этих методах передаваемая последовательность пикселей делится на блоки, в каждом блоке производится преобразование Фурье, устраняются высокие частоты, передаются коэффициенты разложения для оставшихся частот, по ним в приемнике изображение восстанавливается.
Другой принцип воплощен в фрактальном кодировании, при котором изображение, представленное совокупностью линий, описывается уравнениями этих линий.
Более универсален широко известный метод Хаффмена, относящийся к статистическим методам сжатия. Идея метода - часто повторяющиеся символы нужно кодировать более короткими цепочками битов, чем цепочки редких символов. Строится двоичное дерево, листья соответствуют кодируемым символам, код символа представляется последовательностью значений ребер (эти значения в двоичном дереве суть 1 и 0), ведущих от корня к листу. Листья символов с высокой вероятностью появления находятся ближе к корню, чем листья маловероятных символов.
Распознавание кода, сжатого по методу Хаффмена, выполняется по алгоритму, аналогичному алгоритмам восходящего грамматического разбора. Например, пусть набор из восьми символов (A, B, C, D, E, F, G, H) имеет следующие правила кодирования:
A ::= 10; B ::= 01; C ::= 111; D ::= 110;
E ::= 0001; F ::= 0000; G ::= 0011; H ::= 0010.
Тогда при распознавании входного потока 101100000110 в стек распознавателя заносится 1, но 1 не совпадает с правой частью ни одного из правил. Поэтому в стек добавляется следующий символ 0. Полученная комбинация 10 распознается и заменяется на А. В стек поступает следующий символ 1, затем 1, затем 0. Сочетание 110 совпадает с правой частью правила для D. Теперь в стеке AD, заносятся следующие символы 0000 и т.д.
Недостаток метода заключается в необходимости знать вероятности символов. Если заранее они не известны, то требуются два прохода: на одном в передатчике подсчитываются вероятности, на другом эти вероятности и сжатый поток символов передаются к приемнику. Однако двухпроходность не всегда возможна.
Этот недостаток устраняется в однопроходных алгоритмах адаптивного сжатия, в которых схема кодирования есть схема приспособления к текущим особенностям передаваемого потока символов. Поскольку схема кодирования известна как кодеру, так и декодеру, сжатое сообщение будет восстановлено на приемном конце.
Обобщением этого способа является алгоритм, основанный на словаре сжатия данных. В нем происходит выделение и запоминание в словаре повторяющихся цепочек символов, которые кодируются цепочками меньшей длины.
Интересен алгоритм "стопка книг", в котором код символа равен его порядковому номеру в списке. Появление символа в кодируемом потоке вызывает его перемещение в начало списка. Очевидно, что часто встречающиеся символы будут тяготеть к малым номерам, а они кодируются более короткими цепочками 1 и 0.
Кроме упомянутых алгоритмов сжатия существует ряд других алгоритмов, например LZ-алгоритмы (алгоритмы Лемпеля-Зива). В частности, один из них (LZW) применен в протоколе V.42bis.
[ Общее Содержание ]
[ Назад ]
[ Содержание раздела ]
[ Вперед ]
Если Вы не нашли что искали, то рекомендую воспользоваться поиском по сайту:
|