Глава 5. Сетевой и транспортный уровни
5.4. Маршрутизация.
Цель маршрутизации - доставка пакетов по назначению с максимизацией эффективности. Чаще всего эффективность выражена взвешенной суммой времен доставки сообщений при ограничении снизу на вероятность доставки. Маршрутизация сводится к определению направлений движения пакетов в маршрутизаторах. Выбор одного из возможных в маршрутизаторе направлений зависит от текущей топологии сети (она может меняться хотя бы из-за временного выхода некоторых узлов из строя), длин очередей в узлах коммутации, интенсивности входных потоков и т.п.
Алгоритмы маршрутизации включают процедуры:
- измерение и оценивание параметров сети;
- принятие решения о рассылке служебной информации;
- расчет таблиц маршрутизации (ТМ);
- реализация принятых маршрутных решений.
В зависимости от того, используется ли при выборе направления информация о состоянии только данного узла или всей сети, различают алгоритмы изолированные и глобальные. Если ТМ реагируют на изменения состояния сети, то алгоритм адаптивный, иначе фиксированный (статический), а при редких корректировках - квазистатический. В статических маршрутизаторах изменения в ТМ вносит администратор сети.
Простейший алгоритм - изолированный, статический. Алгоритм кратчайшей очереди в отличие от простейшего является адаптивным, пакет посылается по направлению, в котором наименьшая очередь в данном узле. Лавинный алгоритм - многопутевой, основан на рассылке копий пакета по всем направлениям, пакеты сбрасываются, если в данном узле другая копия уже проходила. Очевидно, что лавинный алгоритм обеспечивает надежную доставку, но порождает значительный трафик и потому используется только для отдельных пакетов большой ценности.
Наиболее широко используемые протоколы маршрутизации - RIP (Routing Information Protocol) и OSPF (Open Shortest Path First). Метод RIP иначе называется методом рельефов. Он основан на алгоритме Беллмана-Форда и используется преимущественно на нижних уровнях иерархии. OSPF - алгоритм динамической маршрутизации, в котором информация о любом изменении в сети рассылается лавинообразно.
Алгоритм Беллмана-Форда относится к алгоритмам DVA (Distance Vector Algorithms). В DVA рельеф Ra(d) - это оценка кратчайшего пути от узла a к узлу d. Оценка (условно назовем ее расстоянием) может выражаться временем доставки, надежностью доставки или числом узлов коммутации (измерение в хопах) на данном маршруте. В ТМ узла а каждому из остальных узлов отводится одна строка со следующей информацией:
- узел назначения;
- длина кратчайшего пути;
- номер N ближайшего узла, соответствующего кратчайшему пути;
- список рельефов от а к d через каждый из смежных узлов.
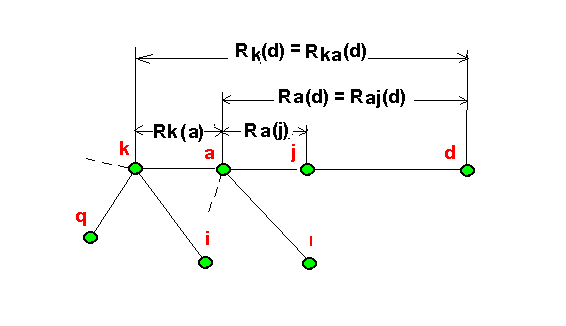
Рис. 5.2. Пояснение к методу маршрутизации RIP
Например, для рис. 5.2 в узле а строка для d выглядит как
d Ra(d) N(d) = j Raj(d) Rak(d)
...
Пусть изменилась задержка Rak(d) причем так, что Rak(d) стало меньше, чем Raj(d). Тогда в строке d таблицы маршрутизации узла а корректируется Ra(d), N(d) изменяется на k и, кроме того, всем соседям узла а посылается сообщение об измененном Ra(d). Например, в некотором соседнем узле l при этом будет изменено значение Rla(d) = Ra(d) + Rl(a). Мы видим, что возникает итерационный процесс корректировки маршрутной информации в узлах маршрутизации.
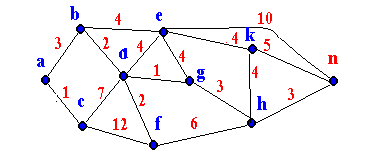
Хотя алгоритм Беллмана-Форда сходится медленно, для сетей сравнительно небольших масштабов он вполне приемлем. В больших сетях лучше себя зарекомендовал алгоритм OSPF. Он основан на использовании в каждом маршрутизаторе информации о состоянии всей сети. В основе OSPF лежит алгоритм Дийкстры поиска кратчайшего пути в графах. При этом сеть моделируется графом, в котором узлы соответствуют маршрутизаторам, а ребра - каналам связи. Веса ребер - оценки (расстояния) между инцидентными узлами. Рассмотрим итерационный алгоритм Дийкстры применительно к формированию маршрутной таблицы в узле а графа, показанного на рис. 5.3 (числа показывают веса ребер).
Рис. 5.3. Сеть для примера маршрутизации по алгоритму OSPF
Обозначим кратчайшее расстояние от а к I через Ri. Разделим узлы на три группы: 1) перманентные, для которых Ri уже рассчитано; 2) пробные, для которых получена некоторая промежуточная оценка Ri, возможно не окончательная; 3) пассивные, еще не вовлеченные в итерационный процесс. В табл. 5.1 представлены значения Ri на последовательных итерациях.
Итерационный процесс начинается с отнесения узла а к группе перманентных. Далее определяются узлы, смежные с узлом а. Это узлы b и c, которые включаются в группу пробных. Включение в группу пробных отмечается указанием в клетке таблицы рядом с оценкой расстояния пробного узла также имени узла, включаемого на этом шаге в число перманентных. Так, для узлов b и c определяются расстояния Rb = 3, Rc = 1 и в для них в таблице отмечается узел а. На следующем шаге узел с минимальной оценкой (в примере это узел с) включается в группу перманентных, а узлы, смежные с узлом с, - в группу пробных, для них оцениваются расстояния Rd = 8 и Rf = 13 и они помечаются символом с. Теперь среди пробных узлов минимальную оценку имеет узел b, он включается в группу перманентных узлов, узел е - в группу пробных и для всех пробных узлов, смежных с b, рассчитываются оценки. Это, в частности, приводит к уменьшению оценки узла d с 8 на 5. Акт уменьшения фиксируется (в таблице это отражено, во-первых, подчеркиванием, а во-вторых, заменой у узла d метки c на b). Если же новая оценка оказывается больше прежней, то она игнорируется. Этот процесс продолжается, пока все узлы не окажутся в группе перманентных. Теперь виден кратчайший путь от узла а к любому другому узлу Х или, что то же самое, от Х к а. Это последовательность конечных отметок в строках таблицы, начиная с последнего узла Х. Так, для узла Х = n имеем в строке n отметку h, в строке h - отметку g, в строке g- отметку d и т.д. и окончательно кратчайший путь есть a-b-d-g-h-n.