| П | О | Р | Т | А | Л | ||||||||||||||
| С | Е | Т | Е | В | Ы | Х | |||||||||||||
| П | Р | О | Е | К | Т | О | В |
Поиск по сайту: Главная О проекте Web-мастеру HTML & JavaScript SSI Perl PHP XML & XSLT Unix Shell MySQL Безопасность Хостинг Другое
|
Местоположение в памятиПолучение адреса шеллкода в памяти - вещь достаточно хитрая. Мы должны найти смещение от регистра
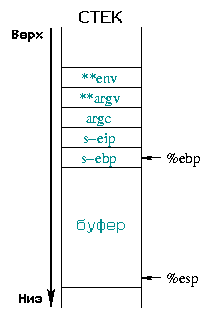
Диаграмма 2 описывает состояние стека до и после переполнения. Вся сохраненная информация (сохраненный
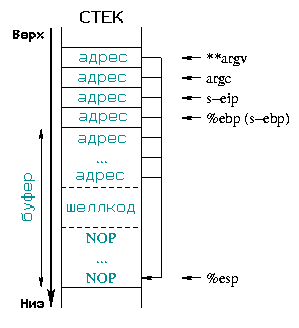
Однако, есть другая проблема, относящаяся к выравниванию переменных в стеке. Адрес длиннее, чем 1 байт, и поэтому сохраняется в нескольких, а это может привести к тому, что выравнивание в стеке не всегда будет правильным. Методом проб и ошибок мы можем найти правильное выравнивание. Так как наш процессор использует четырехбайтные слова, выравнивание может быть 0, 1, 2 или 3 байта (смотри в Части 2 = статье 183 об организации стека). На диаграмме 3, серые части соответствуют записанным 4 байтам. Первый случай, где адрес возврата перезаписан точно, с правильным выравниванием, - единственный, который будет работать. Остальные приведут к ошибке
Если Вы не нашли что искали, то рекомендую воспользоваться поиском по сайту: |
![[буфер]](img/ru_art_03_01.gif)
![[выравнивание]](img/ru_align-en.png)